

Duplicate content in SEO isn’t just about straight-up copying someone else’s work. Quite often, it can happen accidentally due to technical website configurations, CMS settings, and many other reasons.
If your website’s SEO performance isn’t hitting the mark, you might need to take a closer look at your own pages. Replicated copy could be hiding there. SeoProfy won’t let it happen. In this guide, we explore how duplicate content impacts SEO and how you can sort out these issues.
- Mirrored text takes place when identical or similar content appears at different URLs.
- Search engines have limited crawl budgets for each site, and duplicate content wastes these budgets.
- Replicated copies don’t typically result in Google penalties unless they’re created to manipulate rankings.
- Common causes of duplicate content are domain variations, URL formatting differences, parameter URLs, and multiple taxonomy paths to the same content.
- Solutions to fix overlapping text problems include 301 redirects, canonical tags, URL parameters, and noindex tags.
What Is Duplicate Content?
Duplicate content refers to situations where you find the same or similar text on different web addresses, whether that’s on the same website or across various sites.
Here are some examples of replicated copies:
- The exact same content that can be reached through slightly different web addresses
- Identical product descriptions appearing on your store and others
- An article published on multiple pages of different websites, even with permission
Certainly, replicated text is an SEO issue, and as with any SEO issue, it can affect your search visibility. Here’s Google’s position regarding duplicated content:

The Impact of Duplicate Content on SEO
As a website owner or an SEO expert, you might unknowingly create duplicate copies and wonder why SEO doesn’t work. Let’s see why reproduced content is actually a problem and how exactly it creates obstacles on your way to excellent search visibility.
Why Is Duplicate Content an Issue?
Overall, it’s an issue because of how Google works. Search engines aim to display the most relevant results, so when Google discovers multiple URLs of the same content, it faces a dilemma: Which one should it show in search results?
Several types of replicated text can lower search engine rankings:
- Internal duplication in the content is when you have the same content in different parts on your own site. As a result, pages with the same content have to compete for the same audience. You end up with a couple of weaker pages, all trying to steal traffic from one another.
- External content duplication in SEO occurs when other websites feature your content.
How Can Duplicate Content Hurt SEO?
Your identical pages’ positions in search results depend on several aspects:
- Indexing challenges: When Google indexes less preferred page copy or splits rankings between two similar pages.
- User engagement metrics: When users bounce since they encounter the same information repeatedly. This signals to Google that the specific copy doesn’t satisfy the user’s search intent and, thus, doesn’t deserve a high position.
- Decreased crawl budget and diluted link equity.
Let’s look at these last two in more detail. A decreased crawl budget is a limited amount of time Google spends to explore your website. If it has a lot of duplicate content, that’s a waste of time since when search engines keep finding the same text over and over, they:
- Spend precious time on repetitive pages instead of discovering your unique content
- May leave your site without seeing all your important pages
- Can get a bit confused about which version of similar pages should get their attention
And how does duplicate content hurt SEO in terms of link building? Well, here are some ways:
- Divided link power: If the same text appears on different pages, some sites might link to one version while others might choose another. Instead of all these links helping make one main page stronger, they’re spread out across several identical pages.
- Mixed signals for Google: The anchor text in backlinks is instrumental as it lets search engines understand what your page is about. When these signals point to various versions of the same content, this makes it harder for search engines to determine what’s what.
- Misleading link analytics data: Trying to get a clear picture of your backlink profile is a challenge when links are scattered across duplicate content. It’s tough to see how strong your true link power actually is.
Can Duplicate Content Cause a Penalty?
Now, we are closer to the most critical question: Does Google penalize duplicate content? No, and in fact, penalizing replicated text is one of the SEO misconceptions. Google just wants to filter out similar content and display the version it thinks will be most helpful for users.
So, if you notice that your pages aren’t ranking well, it’s not necessarily a duplicate content penalty. Real penalties usually come into play only when there’s clear manipulation involved.
If you’ve experienced the “wrath of Google,” then yes, in this case, you might need to seek Google penalty recovery services or try to recover yourself. SeoProfy can assist you in such a task. Take a look at our latest SEO case to see how we can get your rankings back on track.
What If Someone Scraps Your Content?
This can be incredibly frustrating, especially when you’ve invested hundreds of dollars into creating quality content and Google decided to downrank you. But if you ever come across the idea that if another site’s version of the copy is more authoritative, and Google can rank it higher, it’s one of the SEO myths. Typically, it tries to emphasize the original piece in search results instead of the copycat.
However, in rare cases, you may find that someone’s copy is ranking higher. Here’s what you can do about it:
- Check robots.txt, as this file might be unintentionally blocking Google from crawling some pages.
- Review your sitemap file to ensure you made changes for the specific content that has been copied.
- Double-check your site against search quality guidelines, as even minor technical glitches can hurt your page rankings.
Furthermore, if someone steals your content, you can file a request to remove this page by completing Google’s Legal Troubleshooter.
SeoProfy is a team of seasoned specialists with SEO expertise in a variety of industries. We know how to achieve key business goals for you:
- Higher rankings
- More traffic
- Increased conversions

Common Causes of Accidental Duplicate Content
Unintentional content duplication is something to be aware of so as not to let your Google ranking drop. Here are five main problems that can lead to identical web pages.
Domain and Protocol Variations
When it comes to web addresses, having variations can cause duplicate content issues since the same page can be reached through different URLs. You might find identical content under any of these four links:
- https://example.com/page
- https://www.example.com/page
- http://example.com/page
- http://www.example.com/page
Search engines see these as separate pages, even though the text is exactly the same.
URL Formatting Differences
The way URLs are structured can also lead to trouble with duplicate content if web servers treat them as separate pages. Here are two common issues:
- Case sensitivity: Some servers might see “https://example.com/Product-Page” and “https://example.com/product-page” as distinct URLs
- Trailing slashes: Both “https://example.com/category” and “https://example.com/category/” can display the same content

These tiny differences can confuse search engines because they look like separate pages that happen to share the same content.
Homepage Variations
Index pages can inadvertently create duplicates when they’re accessible via different URLs. For example:
- example.com/
- example.com/index.html
- example.com/index.php
All these URLs usually show your homepage, but to search engines, they might look like separate pages.
Filter and Sort Parameters
On eCommerce sites, URL parameters are often used for filtering and sorting products, which can lead to multiple URLs showing similar content:
- example.com/products?color=blue
- example.com/products?size=large
- example.com/products?color=blue&size=large

Even though these URLs might show slightly different content, search engines often view them as duplicates of the main product page. If not managed well, this can make search engines focus their resources on these variations instead of your original content.
Taxonomies
Content management systems sometimes create multiple paths to reach the same marketing materials. For example, blog posts, articles, or products can show up under:
- Category pages (example.com/category/subcategory/post)
- Tag pages (example.com/tag/topic/post)
- Date archives (example.com/2023/04/post)
- Author pages (example.com/author/name/post)
Each of these paths creates a unique URL pointing to identical content.
How to Find Duplicate Content on Your Site
Without preventive measures in place, duplication can happen on its own, as described above. Fortunately, with the right tools and approach, you can spot any SEO issues and take action to fix them.
A great place to start is by doing a simple search on Google. Just type in “site:yourdomain.com” and then add a specific phrase from the copy you think might be duplicated. If you see several pages in the results with the same content, you’ve found duplication.
There are some handy SEO tools that can help you find duplicate content even faster:
- Copyscape and other plagiarism checkers compare your site against billions of pages to let you know if your text is appearing anywhere else on the web.
- Ahrefs offers a Site Audit tool that scans websites for SEO problems, and duplicate content is among the problems it detects, whether it’s bad-quality pages, title tags, or headings. SEMrush’s Site Audit tool serves a similar purpose.
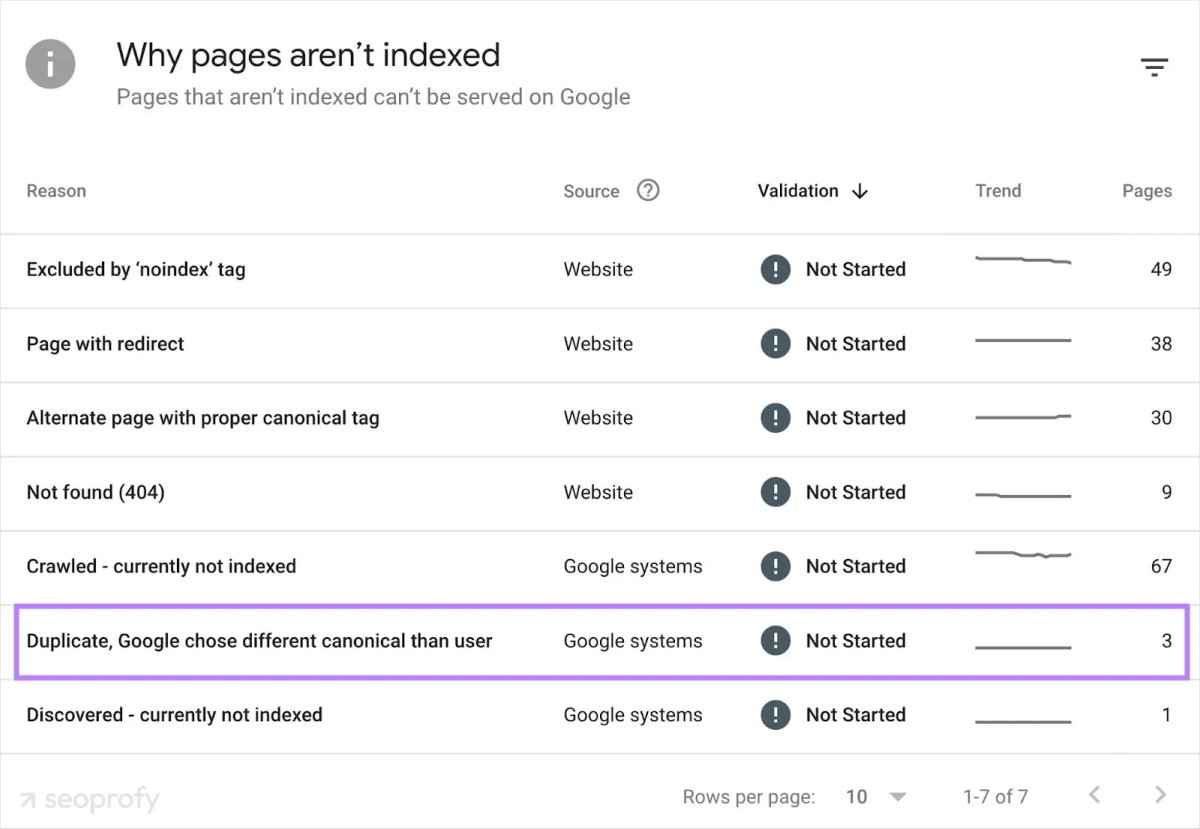
- Google Search Console can indicate identical metadata, like duplicate titles and descriptions, and its Page Indexing report can hint at duplicate issues when explaining reasons for indexing problems.
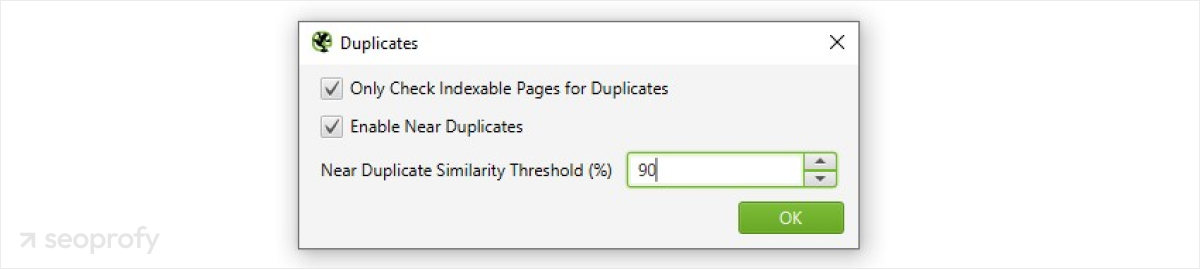
- Screaming Frog SEO Spider can crawl your site and identify pages with identical or very similar content.
How to Fix Duplicate Content Issues
The causes of duplicate pages can vary quite a bit, which means the solutions will depend on the specifics of the problem. If you’ve noticed a sudden drop in website traffic due to duplicated content, here are some common fixes that tend to work.
Make Sure Your Site Redirects Correctly
One of the simplest methods is to make sure your website uses only one version of your domain. Pick either www or non-www and choose between HTTP or HTTPS (we recommend HTTPS for better security). You can also set your server up to redirect all the other versions to your chosen one automatically.
Set URL Parameters
If you run an eCommerce site or any other that uses URL parameters (question marks and equal signs you see in links), you can let search engines know how to approach them with the help of canonicalization and robots.txt. This way, Google will understand when parameters are just duplicating pages and when they’re creating unique content worth indexing.
Implement 301 Redirects
A 301 redirect is often the best solution when you’ve identified duplicate pages. This redirect sends both users and search engines from the duplicate page to the original. Plus, it carries most of the ranking power over to your preferred page, which strengthens your SEO efforts.
Apply the Canonical Tag
Sometimes, it’s okay to have duplicates, for instance, in product variations. In these cases, you can add a canonical tag to the duplicates. It’s an HTML tag that defines the canonical URL for the page and informs search engines that a certain page is a copy and where the original is located.
Use Noindex Tag
Noindex tag tells search engines not to include a specific page in search results. This prevents duplicates from competing with your original content while still allowing users to access the page through direct links. For instance, noindex tag is widely used in shopping cart best practices to prevent search engines from indexing checkout pages.
How to Prevent and Monitor Duplicate Content
Preventing duplications is a lot easier than fixing them later. Here’s how you can avoid duplicate content:
- Plan your site’s structure carefully, thinking about how content will be organized across categories, tags, and archive pages. A clear structure can lessen the chance of creating multiple paths to the same content.
- When you add new features to your website, always test if they might cause duplicate content. For example, if you launch a new product filter (like by color, size, or price), make sure it doesn’t end up generating new URLs for the same items.
- If you run an eCommerce site, invest some time in developing unique product descriptions. While it might be tempting to just use the manufacturer’s descriptions, the original content is unique, and you won’t find it on other stores’ websites (and Google, too).
In addition, we recommend establishing a regular monitoring routine to detect any new duplication problems:
- Schedule quarterly audits of your site specifically focused on content duplication.
- Use tools like Screaming Frog, Ahrefs, and SEMrush to identify duplicate pages automatically.
- Regularly generate Google Search Console’s Page Indexing reports that might indicate duplication issues.
- Consider using plugins or extensions that flag potential duplicate content when you’re publishing new material.
Conclusion
Clearly, SEO isn’t just about optimizing content with keywords. It also implies a significant amount of technical work behind the scenes to ensure search engines can understand, crawl, and index your site. Begin with a thorough audit to identify duplicate content issues across your site and focus first on your revenue-generating pages.
Our professional SEO team can assist you with this task. We use advanced tools to conduct site audits, pinpointing exactly where duplication occurs and developing customized solutions for each of our clients.
Get in touch with us for a free initial consultation and find out more about how SeoProfy can help you rank higher and turn more visitors into customers!

Andrew Shum is the Head of SEO at SeoProfy with 10+ years of experience in SEO and digital marketing. He has been part of the company for over 6 years and has led the SEO department for the past 3.5 years, managing a team of 15+ specialists. He works with competitive and international multi-language projects across eCommerce, SaaS, and enterprise niches, focusing on practical SEO strategies that deliver measurable results.









